Leveraging MongoDB Atlas Vector Search with LangChain





Rate this tutorial


Vector search engines — also termed as vector databases, semantic search, or cosine search — locate the closest entries to a specified vectorized query. While the conventional search methods hinge on keyword references, lexical match, and the rate of word appearances, vector search engines measure similarity by the distance in the embedding dimension. Finding related data becomes searching for the nearest neighbors of your query.
Vector embeddings act as the numeric representation of data and its accompanying context, preserved in high-dimensional (dense) vectors. There are various models, both proprietary (like those from OpenAI and Hugging Face) and open-source ones (like FastText), designed to produce these embeddings. These models can be trained on millions of samples to deliver results that are both more pertinent and precise. In certain situations, the numeric data you've gathered or designed to showcase essential characteristics of your documents might serve as embeddings. The crucial part is to have an efficient search mechanism, like MongoDB Atlas.

MongoDB Atlas is a completely managed cloud database offered on AWS, Azure, and GCP. It has recently incorporated native vector search capabilities for your MongoDB document data. Atlas Vector Search utilizes the Hierarchical Navigable Small Worlds algorithm to execute semantic searches. You can leverage Atlas Vector Search's support for aNN queries to find results analogous to a specific product, conduct image searches, and more.
Atlas Vector Search queries take the form of an aggregation pipeline stage and use the new
$vectorSearch operator. The $vectorSearch stage performs an aNN search on a vector in the specified field. The field you intend to search must be indexed with the Atlas Vector Search vector type. The $vectorSearch must be the first stage of any pipeline where it appears.LangChain is a framework tailored for simplifying the creation of applications employing large language models (LLMs). It is an open-source framework that aids in developing applications powered by language models, particularly emphasizing large language models. The framework extends beyond standard API calls by being data-aware and agentic, which facilitates connections with various data sources to provide richer and more personalized experiences.
This feature enhances the application's ability to interact with different datasets and improve its functionality based on the obtained data. For example, a developer could use LangChain to create an application where a user's query is processed by a large language model, which then generates a vector representation of the query. This vector representation could be used to search through vector data stored in MongoDB Atlas using its vector search feature. The results from MongoDB Atlas could then be returned to the user or further processed by the language model to provide more detailed or personalized responses.
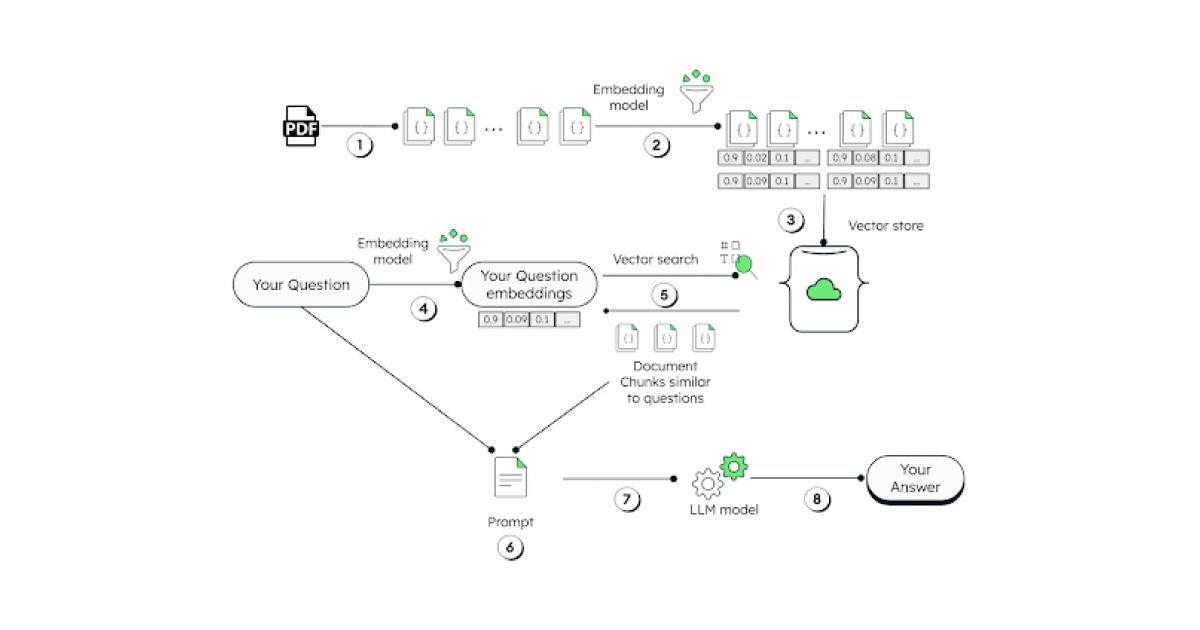
Now, let's consolidate all of these elements in an architectural view.

With the theoretical groundwork laid out, it's time to transition from conceptual understanding to practical application. Let's delve into the implementation process to see how these concepts come to life.
The first step is creating the vector search index. In the Atlas UI (you can also use Atlas Vector Search with local Atlas deployments that you create with the Atlas CLI), choose Search and Create Search Index. Please also visit the official MongoDB documentation to learn more.

Next, utilize the JSON Editor to configure fields of type
vector. I named the field containing the embedding vector embedding.
Specify the namespace (database and collection) on which the vector search index should be created. I chose the namespace
langchain.vectorSearch.The
similarity field in the vector definition specifies the function to use for searching the top K-nearest neighbors. The values can be:euclidean: Measures vector end-point distance for similarity in varying dimensions.cosine: Measures angle-based similarity, independent of magnitude; not suitable for zero-magnitude vectors. For cosine similarity, normalizing vectors and using dotProduct is recommended.dotProduct: Similar to cosine but considers vector magnitude, allowing efficient similarity measurement based on both angle and magnitude. Normalize the vector to unit length at index- and query-time for usage.
You can perform semantic searches on your Atlas cluster running MongoDB version 6.0.11 or later. It allows the storage of vector embeddings for any type of data, alongside other data in your collection on the Atlas cluster. Atlas Vector Search accommodates embeddings up to 4096 dimensions.
Now that we have configured Atlas Vector Search, let's move on to configuring LangChain.
In this article, we will utilize OpenAI to generate vector embeddings. Firstly, you will need the OpenAI API Key. Create an account, and then locate your Secret API key in your user settings.
To install LangChain, you'll first need to update pip for Python or npm for JavaScript, then use the respective install command. Here are the steps:
For Python version, use:
We will also need other Python modules, such as
pymongo for communication with MongoDB Atlas, openai for communication with the OpenAI API, and pypdf` `and tiktoken`` for other functionalities.In our exercise, we utilize a publicly accessible PDF document titled "MongoDB Atlas Best Practices" as a data source for constructing a text-searchable vector space. The implemented Python script employs several modules to process, vectorize, and index the document's content into a MongoDB Atlas collection.
In order to implement it, let's begin by setting up and exporting the environmental variables. We need the Atlas connection string and the OpenAI API key.
Next, we can execute the code provided below. This script retrieves a PDF from a specified URL, segments the text, and indexes it in MongoDB Atlas for text search, leveraging LangChain's embedding and vector search features. The full code is accessible on GitHub.
Upon completion of the script, the PDF has been segmented and its vector representations are now stored within the
langchain.vectorSearch namespace in MongoDB Atlas.
"
MongoDB Atlas auditing" serves as our search statement for initiating similarity searches. By utilizing the <code><em>OpenAIEmbeddings</em></code> class, we'll generate vector embeddings for this phrase. Following that, a similarity search will be executed to find and extract the three most semantically related documents from our MongoDB Atlas collection that align with our search intent.In the first step, we need to create a
MongoDBAtlasVectorSearch object:Subsequently, we can perform a similarity search.
The function returns the most semantically relevant documents from a MongoDB Atlas collection that correspond to a specified search query. When executed, it will provide a list of documents that are most similar to the query "
MongoDB Atlas auditing". Each entry in this list includes the document's content that matches the search along with a similarity score, reflecting how closely each document aligns with the intent of the query. The function returns the top k matches, which by default is set to 5 but can be specified for any number of top results desired. Please find the code on GitHub.MongoDB Atlas Vector Search enhances AI applications by facilitating the embedding of vector data into MongoDB documents. It simplifies the creation of search indices and the execution of KNN searches through the
$vectorSearch MQL stage, utilizing the Hierarchical Navigable Small Worlds algorithm for efficient nearest neighbor searches. The collaboration with LangChain leverages this functionality, contributing to more streamlined and powerful semantic search capabilities. Harness the potential of MongoDB Atlas Vector Search and LangChain to meet your semantic search needs today!In the next blog post, we will delve into LangChain Templates, a new feature set to enhance the capabilities of MongoDB Atlas Vector Search. Alongside this, we will examine the role of retrieval-augmented generation (RAG) in semantic search and AI development. Stay tuned for an in-depth exploration in our upcoming article!